
AI is one of the big buzzwords of the last few years and now a group of researchers at the Stanford Computational Imaging Lab (and including a visiting scholar from Nvidia) are using the technology to develop better holographic displays for AR and VR applications.

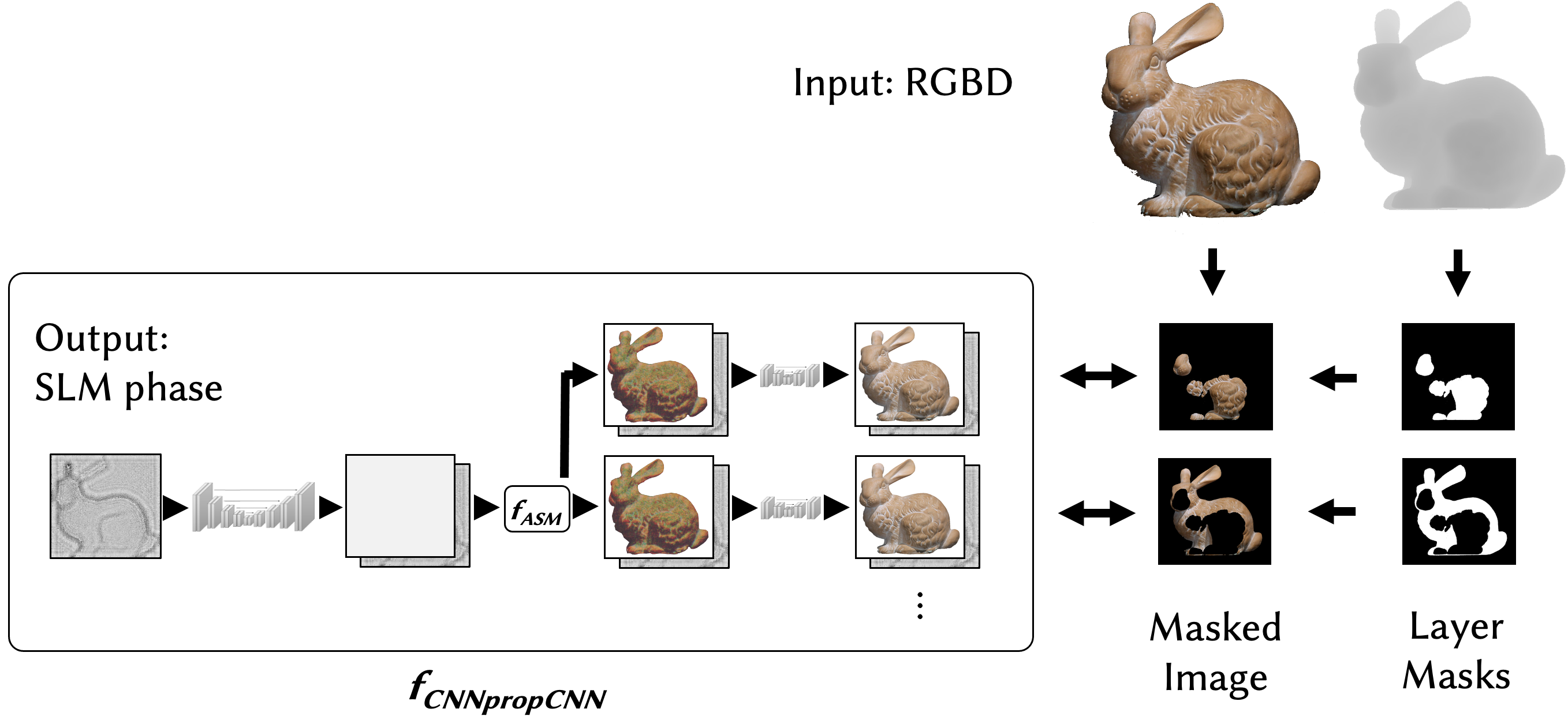
Plenty of researchers believe that holography, which can present a complex light field to the eye, is the best way to get around issues such as the vergence/accommodation conflict (V/A conflict) (where the eye responds to a flat scene on a display differently to the way it would if the same scene was real and different parts were at different depths). However, creating holograms is very, very computationally intensive especially in real time at the kind of resolution needed to portray a realistic image. The algorithm has to calculate the correct phase of the light at the display device for each of the rays in the light field and for each of the depth planes in the image. Furthermore, the images created by this kind of computational process may have artefacts that take away from the ‘reality’ of the image.
For example, some of the algorithms used to generate images can cause speckle in the image – a long term challenge for any laser-based display. Other algorithms tend to reduce contrast in the image. The algorithms used to create the holographic images are all based on different wave propagation models. The Stanford researchers used the idea of exploiting AI learning to compare the computed image to the original using a ‘camera in the loop’ feedback system. This feedback system uses AI to optimise the model to get nearer to the original image and that means that it can take into account factors such as the imperfections and non-linearities in the display device.
 The Stanford display set-up
The Stanford display set-up
Effectively, this technique allows a ‘two stage’ calculation process that creates an image using computation and then uses a simpler correction stage to optimise the image. The Stanford approach uses eight depth planes which is enough to give a ‘near-continuous’ depth representation, alleviating the issues of V/A conflict. The system is exposed to thousands of images with the camera focussed at the different depths to learn the differences between the original image and the generated image.
 Click for higher resolution
Click for higher resolution
The group compared its model to those proposed by other groups and found that it gives better results. The results were presented at Siggraph Asia last month and there is a web page with a large number of comparisons between its method and other proposals here. There is also a brief overview of the presentation of the paper.
The technology was tested both on VR and AR display systems and both showed better results than other methods. Initially the work covered 2D displays but the Siggraph Asia paper highlights the development into 3D scenes.
One area that is of particular interest is that while coherent light sources such as lasers are tricky to use because of issues such as speckle, the same methodology for optimisation can be used to develop systems that use partially coherent light sources such as LEDs and SLEDs (LEDs based on superluminescence) . These can be attractive light sources, but can result in blurred images and a lack of contrast compared to laser light sources. The Stanford approach gets around these disadvantages and the group has created high quality 2D and 3D images using these light sources.
There are some good images of the results of the process and comparisons with other methods here.
The project at Stanford has been funded by Ford, Sony, Intel, the National Science Foundation, the Army Research Office, a Kwanjeong Scholarship, a Korea Government Scholarship and a Stanford Graduate Fellowship. (BR)