Yahya Mirza from Aclertic Systems began the conference with a discussion of the computational needs for rendering light field images. His company’s goal is to “better understand what it takes to create content for future light field displays and look for opportunities to automate complicated and time consuming processes so holographic productions can be more economically viable.”
To get there, Mirza is developing plug-ins for special effects and compositing tool sets and working with Intel to build a state of the art processors to support such rendering. It is still early in development, but he has a 9-layer approach to rendering synthetic light fields that can include very hard-to-render items such as smoke, transparency, glass, textured metal surfaces and more. He then showed some rendering of the Virgin Galactic spacecraft and a logo for the new Red Hydrogen phone which features a 4-view lightfield (like) display. He says the display needs left/right narrow and L/R wide stereo pairs to create the image. His tools can create custom camera arrays that are matched to to the display.
One particular hardware bottle neck they are addressing is the i/o need for huge datasets. This will initially be based on COTS hardware but will hopefully migrate to FPGAs and software.
Ryan Overbeck from Google delivered a talk that was quite similar to one he gave recently at Siggraph. This described Google’s two light field capture rigs. One is a half circle of camera that spins in a circle and the other is a pair of DSLR camera that spin in a spiral pattern. This is good for capturing static scenes and creates a navigatable volume that that is less than a meter all around. Nevertheless, they have used the rigs to capture some very compelling scenes like the space shuttle flight deck and a couple outside of their tiled home.
Overbeck brought one of the rigs to Display Summit and allowed attendees to see this content on a Vive headset. It is clearly some of the best light field content available and it is now available on the Steam VR site along with their SDK. He also described a number of tricks they developed to help improve the images which are amazingly sharp and clear even in the modest resolution Vive headset.
The lightfield data set is rendered in realtime to create the stereo images needed for the headset at 90 fps. In development now are methods to extend the concept to capture video.
Arianne Hinds from CableLabs stated they represent the cable industry and their job is to look at the big picture, understand trends in use cases, and have the infrastructure and technology ready to support new uses as they become viable. She sees light field capture and delivery as one important trend they are preparing for.
She then laid out her assessment of the requirements for commercial adoption of light field systems, as shown in her slide below. The most important take away is that extending the current 2D video paradigm to many cameras, i.e. a spatial representation of light field images, is not the way to go. She believes that even live capture with cameras will need to be transformed into a game engine-like model for efficient compression and distribution.

Hinds detailed a number of issues with using a raster approach to light field capture including the lack of a clear “ground truth” to measure various compression schemes against. This was a clear jab at the JPEG Pleno approach which is currently evaluating compression of sparse camera data and comparing it to a ground truth of the original dense camera data.
CableLabs is throwing its support behind a file format called Orbix. This was developed by Otoy as a big “container” to carry all kinds of graphic and special effects data to make it easy to interchange files between facilities. CableLabs plans to work with partner to develop a light field standard around this format and in fact, used Display Summit to announce plans to form a new consortium to further this effort.
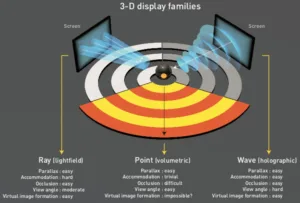
Zahir Alpaslan from Ostendo then gave an overview of what the JPEG-Pleno group is working on. He started by categorizing advanced images into three groups: ray-based, point clouds and wave-based. Ray based is what most people refer to as light fields, with point clouds generally used to create depth and/or volume information, that might be used in conjunction with other data. Wave-based refers to true holographic images. The JPEG-Pleno effort is aimed at developing a framework that will facilitate the capture, representation and exchange of all three types of images. But, the focus in the initial phase is on ray-based solutions. (for more on point clouds, including what JPEG is doing see our article from IBC Immersive Media at IBC)
Most of the work today is focused on developing a codec that can take a series of sparse camera images from multiple cameras or single cameras with microlens arrays, compress/decompress and compare to a high fidelity array of images (at nxn). This nxn array becomes the Ground truth images that CableLabs thinks is not a real ground truth.
Alpaslan noted that the JPEG-Pleno effort supports parallel processing that will likely be needed for tiled light field display solution (the heterogenous computing environment later described by FoVi3D). And, they can achieve extremely high compression ratios (he quoted 0.0001 bits per pixel).
The group is current working to evaluate codec using subjective (test subjects) and objective (SSIM or Structural SIMilarity) metrics. More test subjects are needed for their experiments. He concluded by noting that point clouds remain immature and that terapixels will be needed to move to true holographic solutions.
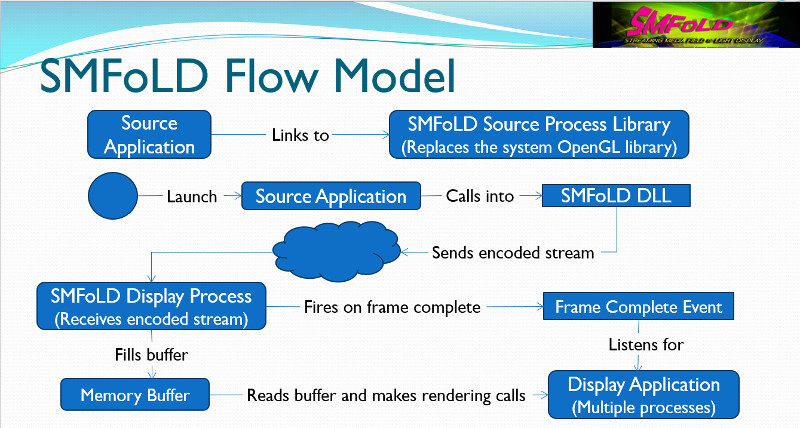
Tommy Thomas from Third Dimension Technologies (TDT) gave an update on progress they are making on the development of the stream media standard for field of light displays (SMFoLD). This is an effort funded by the Air Force Research Lab that addresses the need to have a common interchange format for light field data. Clearly, the military has lots of data sets that create 3D images, so having a way to share these more efficiently is a key need.
The TDT approach relies on using OpenGL for the interchange interface, which means light field data is represented as geometries and textures. They propose to develop a customized library that will add some of the functionality needed for light field display light camera position, angle, field of view, etc. This approach allows the source to send one type of data and the display to render it based on its unique capabilities. The display could be 2D, a stereoscopic 3D, horizontal-only parallax multi-view 3D, or a full light field display. Each display would write its own API to allow this to happen. TDT is now in the process of proving that a single source data stream can drive two different 3D display types.
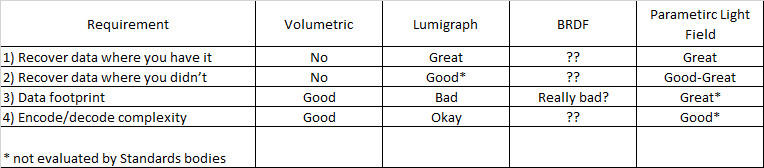
Ryan Damn is from Visby, a start up in the Light Field space. He started by showing some light field capture solutions but concluded that these cameras “massively under sample,” which complicates the representation and delivery part of the chain. His then focused on evaluating several advanced 3D representations to better understand how they perform for compression, delivery and decompression (see criteria in chart below). Four representations were evaluated – volumetric, image-based renderer (Lumigraph), BRDF and Parametric Light Field (their area of focus).

Volumetric is good for shape data but pixel data is inherently Lambertian. This approach can only work to create a high fidelity 3D image if you can simulate all the physics of the materials and environment.
Image-based rendering, the so-called lumigraph approach, uses an array of camera of a single camera with a microlens array to capture images. As noted above, it massively under samples the image so reconstruction/interpolation of light rays is needed.
The Bidirectional Reflectance Distribution Function (BRDF) refers to the light reflecting properties of materials. Theoretically, models can be developed of all materials to understand how light from difference light sources is reflected in all directions. This can allow for development of complex ray-tracing models to provide a simulation of the light from a scene that includes reflections, transparencies, speculars, etc. It is a massive computing effort and requires complete knowledge of the materials in the scene, but can then be used to quickly relight the scene and/or change materials. Damn admitted he did not know enough about this option to properly evaluate it.
Damn said Visby are focused on parametric light fields, which he says addresses the deficiencies of lumigraphs (under sampling problems, no representation of smoke, mist or water, lack of true depth data and high data rates). He then tried to explain a parametric light field, but he did not do a good job in explaining it. It seems to mean to use ray tracing using a series of basis functions (with different basis functions for various materials types) to improve the fidelity of the 3D image . The benefit? Parametric light field will be orders of magnitude smaller in terms of file size and there are no geometries or textures to transmit. Plus, the complexity of the encode/decode is similar to H.264.