Artificial Intelligence (AI), Machine Learning and Deep Learning were topics that emerged at NAB that were covered in several sessions we attended. These included:
- The Future of Cinema Technology session titled “How You Get Inside It: AR/VR/AI and Deep Learning-The Immersive New Media Landscape and the Solutions Needed to Get Us There
- An NAB Super Session titled, “Intel Presents: There’s Revolution in the Air — How Technology Is Transforming Media, Entertainment and Broadcastingˮ
- An NAB Super Session titled, “Next Generation Image Making – Taking Content Creation to New Places.”
The Future of Cinema session featured AI specialist Lionel Oisel from Technicolor who helped set the stage with some definitions of AI. The first is a rules-based system, such as a game engine where certain choices are offered and the system can only respond in limited ways. The second he called machine learning where the machine is presented a large number of examples of what you want to teach it. If you want it to recognize cars, you provide images of thousands or millions of cars of all shapes and sizes from different angles, lighting and other conditions. It can then recognize a car in an arbitrary image. The third category is deep learning. It takes the car example even further by continuing to collect car images and correcting errors in previous identifications or classification of cars. It is unsupervised or predictive learning. In other words, it is learning from its mistakes, just as humans do.

The above are sub-categories of AI, which might be defined by the ability to pass the Turing test – i.e. can I tell if the responses I received to a question were from a human or a machine? If not, the system must have AI.
Today’s VR experiences are mostly in the game category – a limited set of options and responses. But if we can apply AI techniques, it might allow the user to impact the virtual world they are in.
One idea is to use AI to “offload some of the compute intensive processes in VR like particle effects simulation”, stated Arjun Ramamurthy of 20th Century Fox.
Kevin Bolen, immersive and interactive audio designer at Skywalker Sound said, “I think the next generation is an artificial character that responds and interacts appropriately based on what the player does. This will give us a chance to create interesting experiences.”
“With VR, it feels like the experience isn’t enough. You want to leave your mark on the world and share your experience. I think AI is going to allow us to do that,” noted Jacqueline Bosnjak, CEO of sound technology company, Mach1. Her company is working on a project that’s using AI to drive its narrative, she said, “Suddenly, you are the protagonist. I think this will take VR out of the novelty phase and into this place where you are in the metaverse.”
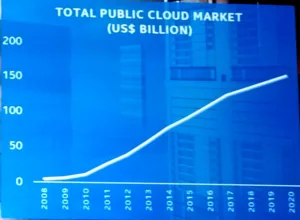
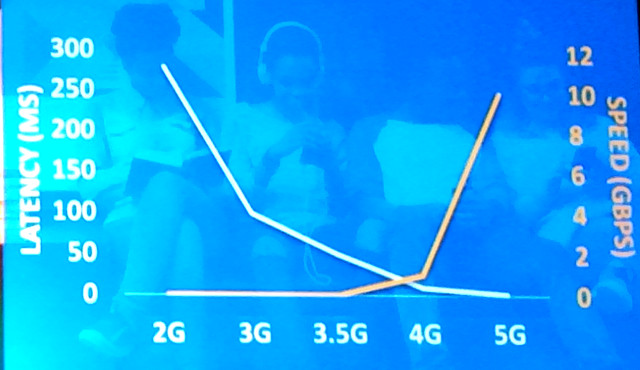
The Intel Super Session was hosted by Jim Blakley, general manager of the Visual Cloud Division at Intel Corp. Blakley said that computer generated content for Hollywood movies has been progressing at an incredible pace, that is, following Moore’s Law, with Intel providing the computing power to enable this. Now, this is moving to the cloud and when used for video it’s called the visual cloud. Obviously, major players such as Netflix, YouTube and AWS are key players here, but VR and AR are also going to be important drivers, he said.
He then showed two charts showing the growth of the public cloud market along with trends for wireless speed and latency. These last two factors will be incredible drivers for new visual cloud services.
In AR/VR, Blakely noted that Intel has acquired a video stitching company recently and it has its RealSense 3D capture solution as well. He said light field capture is coming for AR/VR as well as AI/deep learning.
The AI/deep learning part is particularly interesting to Intel. Toward that end, it used NAB to announce a $4.125M program with Carnegie Mellon University (CMU) to increase their understanding of visual cloud. The work will look at creating histograms of video frames to identify and learn objects and images to be able to do complex statistical analysis on images. New types of experiences, such as augmented reality, virtual reality and panoramic video require new capabilities in terms of system architectures and data processing techniques.
Intel is creating the Science and Technology Center (ISTC) for Visual Cloud Systems at CMU, with funding for about 11 researchers, 10 of whom are at CMU and one at Stanford University in California. Stanford is contributing computational photography and domain-specific language expertise. The funding is for three years, at which time they will re-evaluate it, but Blakley said they intentionally kept the term short in order to get a fast turn-around.
Computation photography refers to work Intel is doing on outside-in multi-camera capture. Blakley showed how they can create a 3D model of a stadium by arranging cameras all around the venue. Such capabilities are used mostly for replay now allowing the camera view to swing around the player to view the action from any angle. (for more on this, see our comments on the demos at CES – Intel Focuses on VR at Press Event)
In the “Next Generation Image Making” session, Gavin Miller, head of Adobe Research said that his area of focus is on using machine learning to “explore ideas more quickly for story telling creatives.” That means developing tools in the lab that will likely show up in Adobe products shortly thereafter. This includes using AI to make the tools invisible, having fewer steps to achieve a task and creating interactive agents.
He then presented an example where machine intelligence can be applied to the film making process. The example was the need to replace a drab sky captured in the original footage with one that the director preferred. The first step is semantic segmentation to identify the section of the frame to be replaced, mask this section and then begin the search of stock footage of sky that matches this mask shape. Machine and/or deep learning is needed to build up these databases of images to make this task easier.
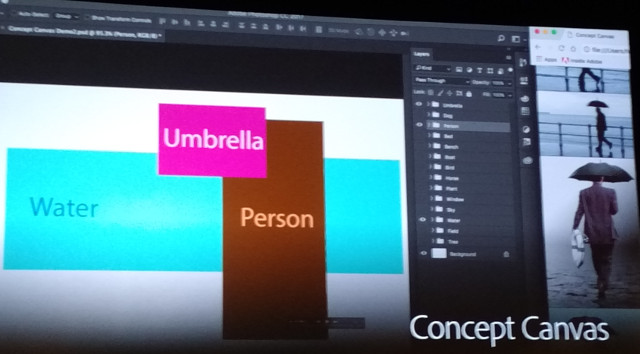
His second example described what Adobe calls “Concept Canvas”. This is a project to use key words and object relationships to search visual database for images to use in storytelling. He described how the tool allows the creator to look for shots of a person with an umbrella near water, with the positions of these objects roughly defined in the frame as well. He also described an example with person and a dog – and the ability to swap their positions to find the footage desired.
Finally, he showed a tool in development that places markers all over a VR 360º frame to construct a 3D model. This can then be used to smooth a jitter camera movement or fix the camera position.